
We understand the critical role Oso plays in our customers' applications. We built the system to be highly reliable and resilient. The read path in particular, which is what applications use with every authorization, is designed to be as simple as possible. This post outlines how we think about reliability and resiliency, and the trade-offs we consider to ensure customers do not experience any disruption.
Reliability
We define reliability as the ability of the system to meet our customers’ expectations in terms of availability and latency.
Cell-Based Architecture
Oso runs using a cell-based architecture to minimize the dependencies to service authorization read requests. Each instance of the Oso service is deployed alongside a backing SQLite database. This has two benefits:
- Data access is local to the server, reducing the overhead of network latency and thus overall latency.
- The server’s availability is not impacted by any upstream dependencies.
There are no external dependencies on the read path, as everything for a read is contained within a cell; there are no hops, even to other AWS services like RDS. There are a few dependencies for other paths: S3 to bootstrap a server, Kafka for writes, and SQS for non-critical features such as an Oso Sync. We tolerate dependencies on these services because they are battle tested and because these paths are less sensitive than reads.
Additional details of the Kafka architecture can be found on this blog post.
Availability
Over the period from Oct 21, 2024 to Oct 21, 2025, Oso’s synthetic monitoring, which performs an authorize query every minute from twelve regions, measured uptime exceeding 99.99%.
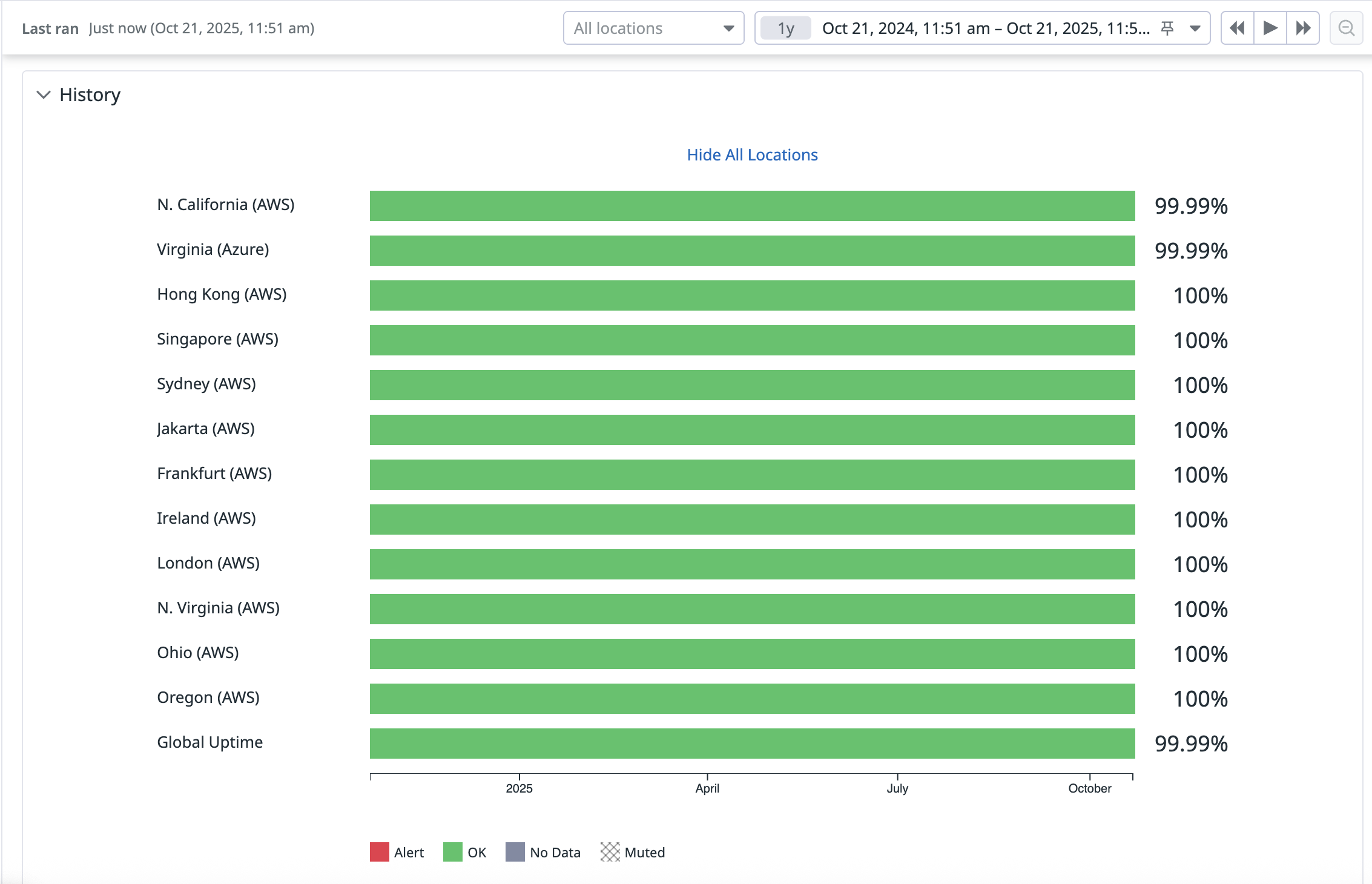
Read Resilience
Oso’s cell-based architecture allows us to scale out quickly to meet increases in read volumes and deploy to additional regions as needed.
In the event of a burst of traffic, Oso’s systems are configured to increase the throughput capacity automatically in minutes, preventing service degradation. If additional capacity is required, our alerting system will notify the 24x7 on-call engineer if the system is struggling to keep up with the volume. We monitor system-level metrics such as CPU utilization and application-level metrics such as latencies and errors. With manual operations, we can further scale out the throughput capacity in 10 minutes to meet the customer request volume.
In the event of an application bug, our alerting system will notify the 24x7 on-call engineer for increase in errors. We can rollback to a known valid version in under two minutes.
Write Resilience
When Oso receives a write, it first publishes it to a global Kafka cluster. All servers consume from the global Kafka cluster to apply the write to their local databases. This design enables us to maintain total ordering of writes and to accept more writes per second than can be persisted to the local database in bursty situations.
The rate at which data can be written to the local database is variable, dependent on the shape of the data and the amount of data being updated. In the event that Oso receives a burst of write requests that exceeds the rate at which they can be persisted, servers may experience replica lag, measured as the time between when a message is published to Kafka and when it is persisted to the local database. A server that is experiencing high replica lag may use stale data to answer authorization queries.

The trade-off of the design is that there is a higher baseline latency for all writes as each write needs to make a round-trip through the global Kafka cluster. In practice, we observe that the worst cases are up to 1s, and it varies based on proximity to our global Kafka cluster.
Fallback
Network outages, critical application bugs, or other issues that prevent customers from reaching Oso Cloud can happen. We make sure we are prepared for those incidents. Oso Fallback can be deployed as a container in the customers’ infrastructure and periodically retrieves a full copy of the database. This means that the local copy of the database should remain less than 30 minutes stale as long as snapshots can be retrieved. If configured, the Oso SDK will automatically attempt requests against the local Fallback cluster if requests against Oso Cloud are failing.

Performance
Oso Cloud’s core engine compiles the Polar policy and authorization query into SQL and executes the SQL against an embedded SQLite database to produce the result. Changes we make to application code or to the SQLite engine may impact the overall performance of authorization queries. All changes must pass tests before they can be merged and deployed. Additionally, changes to the read path must also be run on our traffic mirror to measure any deviations from current performance.
Oso engineers are continually monitoring the performance of queries in production to ensure we are meeting our internal service level objective of having P90 of all authorize requests complete in under 10ms. While Polar’s expressiveness is a good fit to capture any authorization use case, additional optimizations are sometimes required for the queries to complete quickly. For example, we recently observed that the P90 of a specific customer’s authorize requests was regularly exceeding 50 ms. We determined that due to the shape of their data, their queries would benefit from using a different index distribution. Applying the optimization, we brought the latency of the same queries down to 4ms.

Oso handles our queries with consistent sub-10ms latency no matter where our users are in the world, and all with no downtime.
Nick Laferriere, Head of Engineering
Conclusion
Authorization is a critical part of our customers’ infrastructure. With that in mind, we have invested in preventing and minimizing disruption. As this blog outlines, reliability and resilience are core design principles that shape our architecture and our operational processes.
Aside from architecture considerations, we know that our customers’ trust and feedback is vital for us to continue to improve the system. Customers can follow our status page here and can always dive into the details of our system in our documentation.
Frequently asked questions
